In the early days of SEO, the rules were simple: let Google in, or stay invisible. But it’s 2026, and the game has changed. Today, your website isn’t just being crawled by search engines; it’s being ingested by Large Language Models (LLMs), training sets, and generative agents.
This has created a massive tension for brand owners and marketers. On one hand, you want to protect your intellectual property and prevent AI companies from “stealing” your content to train their models for free. On the other hand, if you block every AI crawler, you disappear from the very platforms where your customers are now searching: ChatGPT, Claude, Perplexity, and Gemini.
This balance is what we call AI Crawler Governance.
Most companies are currently getting this wrong. They are either wide open to exploitation or completely invisible to the future of search. At Citemetrix, we’ve analyzed thousands of domains, and we’ve seen a recurring pattern of errors.
Here are the 7 biggest mistakes you’re making with your AI crawler policy and how to fix them before your visibility hits zero.
1. Treating Governance as a Purely Technical Task
Many organizations hand off “crawler management” to the IT or security team and wash their hands of it. The result? A developer sees a spike in bot traffic, gets worried about server load, and adds a Disallow: / to the robots.txt file for every AI user-agent they can find.
The Mistake: Approaching crawler access as a technical security problem rather than a strategic business decision.
The Fix: Recognize that managing AI scrapers is a policy choice. Your Marketing and SEO teams need to be the primary stakeholders. Before a single line of code is changed, you need to decide: Is the traffic/visibility from this specific AI engine worth the content it consumes?
At Citemetrix, we recommend a “Visibility First” mindset. If an AI engine (like Perplexity) provides citations and drives traffic, it should be treated differently than a “scraper” that only trains a model and never mentions your brand.
2. Lacking Clear Ownership and Accountability
Who owns your brand’s presence in AI models? If you don’t have an answer, you’re already behind. When nobody owns the policy, the policy drifts. You might have blocked GPT-Bot six months ago because of a news headline, but now that SearchGPT is a major traffic driver, that block is actively hurting your revenue.
The Mistake: AI crawler policies are often “set and forget,” with no single person responsible for the outcome.
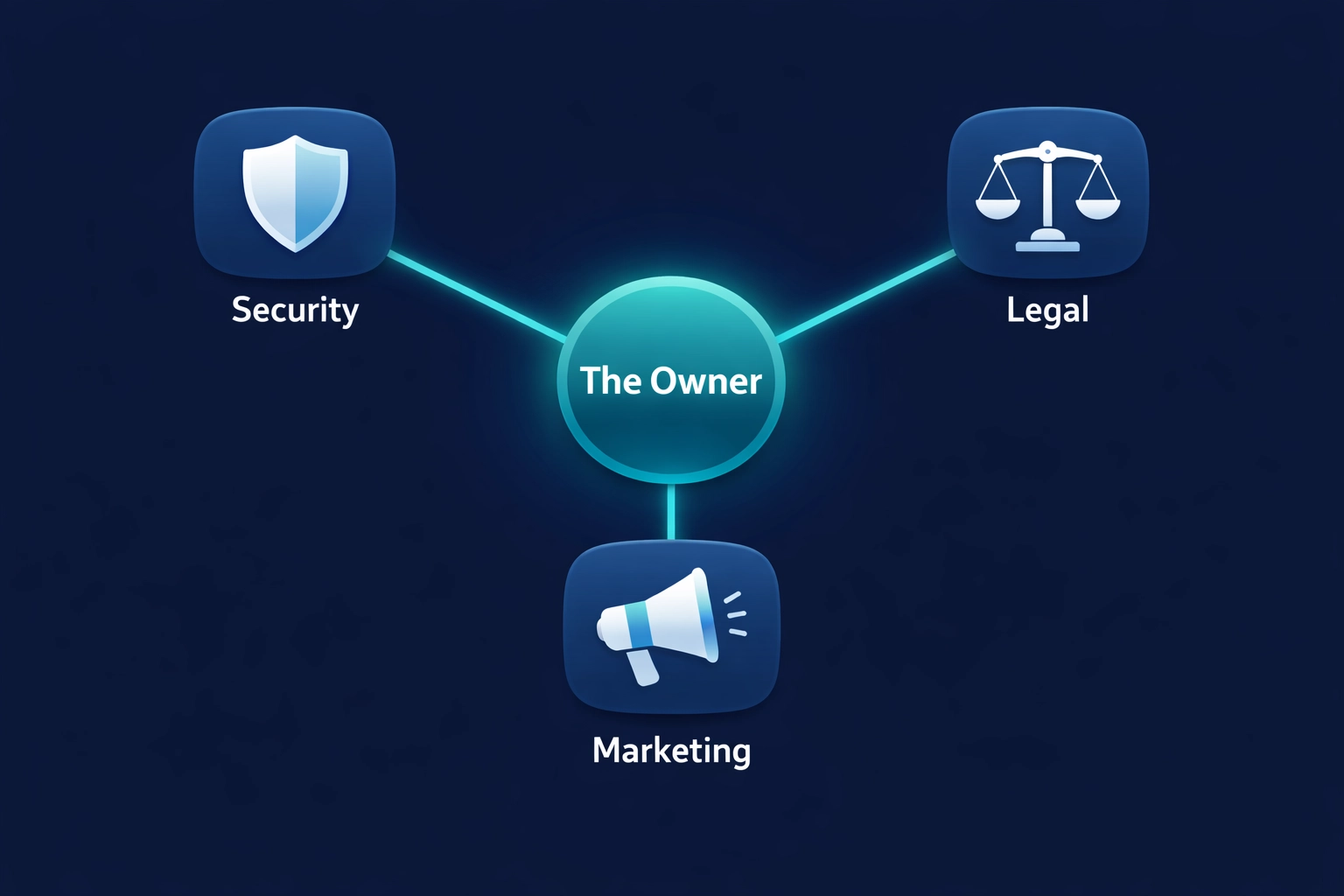
The Fix: Assign a single accountable owner: usually your Head of SEO or Digital Marketing: to manage AI Governance. This person should work with Legal (for IP protection) and Security (for server health) to treat crawler access as a “living standard.”
3. Operating Without a Measurement Baseline
How much of your traffic is actually coming from AI crawlers? Which models are citing you most often? Most brands have no idea. They are making sweeping decisions to block or allow bots without looking at the data first.
The Mistake: Deploying crawler policies without understanding your current crawl-to-referral ratio.
The Fix: Use AI Crawler Monitoring to establish a baseline. You need to know which bots are hitting your site, how often, and: most importantly: if those hits result in your brand being cited in AI responses.
Inside the Citemetrix dashboard, we track these patterns for you. By comparing crawl frequency with your ModelScore™, you can see if a specific crawler is actually helping your visibility or just taking up bandwidth.
4. The “One-Size-Fits-All” Blocking Approach
In mid-2024, there was a massive wave of websites blocking “all AI bots.” It was a panic response to copyright concerns. But not all bots are created equal. There is a huge difference between a training crawler (which uses your data to improve a model) and a search crawler (which uses your data to provide an answer to a user right now).
The Mistake: Blocking all AI crawlers indiscriminately, leading to a total loss of Generative Engine Optimization (GEO) potential.
The Fix: Implement a declared posture for different crawler categories. We recommend a three-tier system:
- Search/Action Crawlers (e.g., PerplexityBot): Generally Allow. These lead to direct citations and traffic.
- Training Crawlers (e.g., GPT-Bot): Condition-based. Allow if you want your brand’s facts to be “remembered” by the model; block if you have high-value proprietary data.
- Aggregator/Unknown Scrapers: Block. These provide no benefit to your brand.

5. Relying Solely on Robots.txt
The robots.txt file is essentially a “gentleman’s agreement.” Most reputable AI companies (OpenAI, Anthropic, Google) will respect it, but many smaller, more aggressive scrapers will ignore it entirely. Furthermore, robots.txt is public: it tells everyone exactly what you are trying to hide.
The Mistake: Thinking that a line in your robots.txt is enough to enforce your AI governance policy.
The Fix: Use a multi-layered approach. Pair your robots.txt signals with a technical enforcement layer, such as a Web Application Firewall (WAF).
More importantly, adopt the new industry standards. We strongly suggest setting up an llms.txt file. This is a new proposal (inspired by robots.txt) that provides a markdown-based summary of your site specifically for LLMs. It allows you to tell the AI exactly what your most important information is, ensuring that when it does crawl you, it gets the facts right.
6. Zero Ongoing Observability
The AI landscape moves faster than any technology in history. A bot that was harmless yesterday might be part of a new “search” product tomorrow. If you aren’t monitoring your logs and your AI citations in real-time, you are flying blind.
The Mistake: Setting a policy and never checking if the crawlers are actually complying or how they are characterizing your brand.
The Fix: Establish an observability workflow. You should be checking your AI Crawler Monitoring reports at least once a month. Are you seeing new user-agents? Is your ModelScore dropping because a major model can no longer access your site?
Ongoing monitoring allows you to detect “policy deviations”: cases where a crawler you thought you blocked is still hitting your server, or where a “good” crawler is failing to index your most important pages.

7. Failing to Update Policies for the “Quarterly Shift”
The rules of Generative Engine Optimization (GEO) change every time a new model version is released. When GPT-5 or the next Claude update drops, the way they interpret your site’s data will change. If your governance policy is a year old, it’s ancient history.
The Mistake: Treating AI governance as a static document rather than an evolving strategy.
The Fix: Implement a formal review cadence. At Citemetrix, we recommend a quarterly review of your crawler registry and your AI visibility metrics.
Ask yourself these three questions every 90 days:
- Are there new AI players in our industry that we aren’t currently allowing?
- Is our
llms.txtfile updated with our latest product info and brand messaging? - Does our current “block list” still make sense given the traffic we are seeing (or losing)?
The Path to Smart AI Governance
The goal of AI crawler governance isn’t just to “stop bots.” It’s to ensure that when an AI speaks about your industry, it speaks about you.
If you block the world, you stay safe, but you also stay silent. If you open the doors completely, you lose control. The “middle path”: smart governance: is about using data to decide who gets in and how they represent your brand.
How Citemetrix Helps
We built Citemetrix to give you the data you need to make these decisions. Instead of guessing, you can:
- Monitor AI Crawler Activity: See exactly who is visiting and how often.
- Track Citations: Know if those crawls are turning into brand mentions.
- Analyze Sentiment: Understand how the AI is “characterizing” your brand to users.
- Optimize Visibility: Use our ModelScore™ to identify gaps in your AI search presence.
Don’t let your AI visibility happen by accident. Take control of your crawlers, protect your data, and make sure your brand is the one the AI recommends.
Ready to see who’s crawling your site and what they’re saying?